Abastract
在IFDS出现之前,经典intra-procedural analysis框架(D,L,F)对于程序分析问题的研究还停留在①多项式时间处理specific individual problem比如constant propagation/pointer analysis②多项式时间处理locally separable proble(经典bit-vector/gen-kill问题——reaching definitions,available expressions,live variabl的过程间分析)③对普遍分析问题提供非多项式时间的算法方案。
随着POPL'1995发表的Precise Interprocedural Dataflow Analysis via Graph Reachability通过将一类inter-procedural analysis问题转化为a special kind of graph-reachability problem图可达性问题——IFDS框架横空出世。IFDS除了针对separable problems,还针对包括truly-live variables,copy constant propagation,possibly-uninitialized variablestruly-live variables在内的non-separable problems等一大类普遍性分析问题都提供了多项式时间的精确解决手段。由于IFDS本身的约束,作者在Theoretical Computer Science'1996上还发表过一篇Precise interprocedural dataflow analysis with applications to constant propagation提出IDE框架来处理interprocedural constant propagation等IFDS框架处理不了的non-distributive问题。这两篇论文为程序分析领域引入新的血液。
近年Sparse Value IFDS,Disk-Assisted IFDS等课题一直是学术界的研究热点。在工业界比如phasar等程序分析工具中IFDS/IDE也有具体实现。
CFL-Reachability
首先介绍图可达性的概念。
Feasible and Realizable Paths
过程间数据流分析真正用于工程落地之后的复杂度往往是很高的,即ICFG的边出现路劲爆炸导致分析速度变慢。究其根本原因,是因为在这些edges中有一些属于不可达边——Infeasible paths。
Paths in CFG that do not correspond to actual executions is Infeasible paths.
如果我们能够尽可能的防止CFG被Infeasible paths所污染,让分析流图边的更加简洁,势必大大提升分析速度。但是实际情况下这种infeasible paths往往无法判定。
1 | foo(int age) { //age只会是Positive,所以一条分支肯定不会被执行 |
Realizable Paths
The paths in which "returns" are matched with corresponding "calls".
如果一条调用边,其return-edge可以正确匹配到其call-edge,则称这条边是realizable的。既然infeasible不可判定,便引入其子集——因为realizable paths可能不会被执行到,但是unrealizable paths则一定不会被执行到,而unrealizable paths则是可判定的。
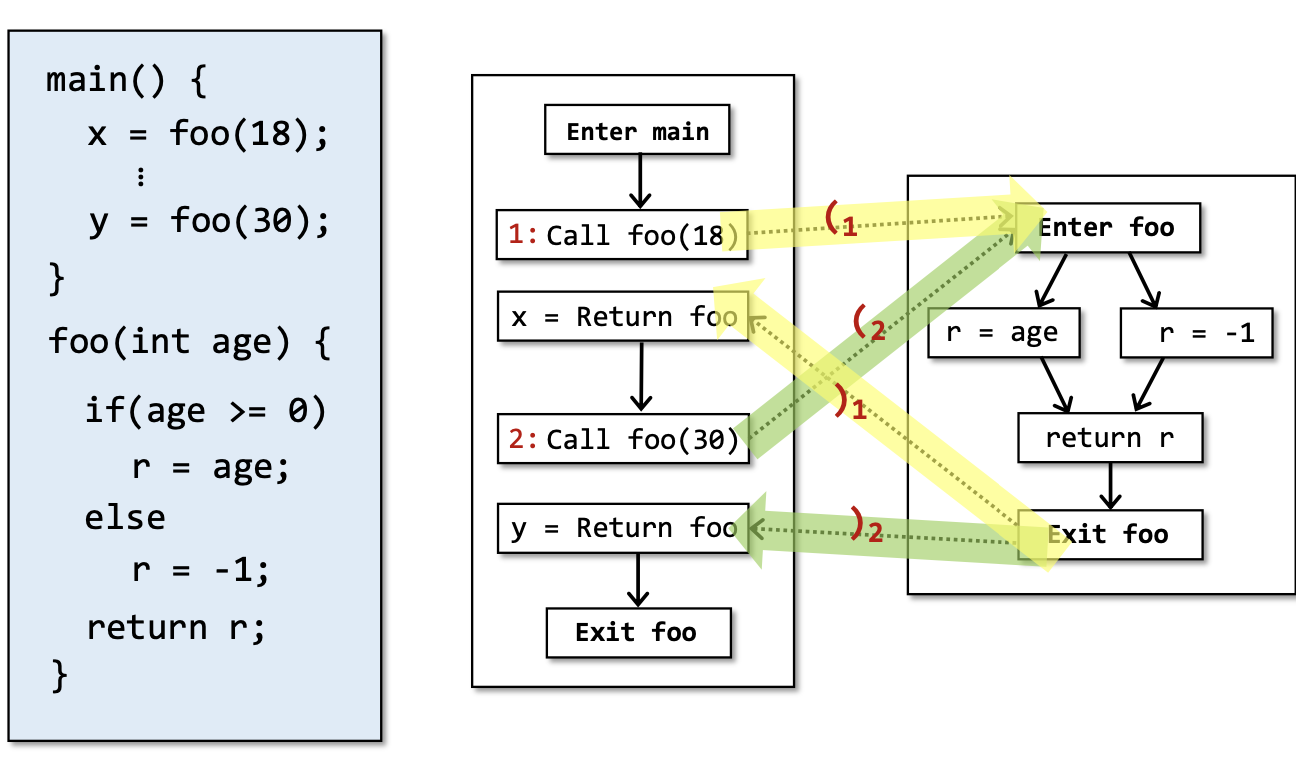
寻找这样的realizable paths来是IFDS顺利执行的前提,下面引入一种系统的方式识别realizable paths——CFL-Reachability。
CFL-Reachabiligy
A path is considered to connect two nodes A and B, or B is reachable from A. Only if the concatenation of the labels on the edges of the path is a word in a specified context-free language.
对于A和B两个node之间有一条path(一系列edge组成的,换句话说B可达A)并且这条path上的所有edge的labels构成的单词是由事先规定的context-free language定义好的合法单词的话,就说B is CFL-Reachable from A.
context-free grammer
上下文无关语言context-free language指的是由上下文无关文法context-free grammer产生的语言。
上下文无关文法是一种形式语言用于描述某种语法,它的主要形式就是:S ⟶ 𝞪. 这是一种产生式。S代表非终结符而𝞪代表一系列终结符或者空格。比如CFG的文法如下的话:
- S ⟶ aSb
- S ⟶ ℇ
这里的𝞪就是aSb/ℇ,上下文无关context-free的意思就是说在任何出现S的地方都可以使用aSb/ℇ来替换。
Partially Balanced-Parenthesis Problem
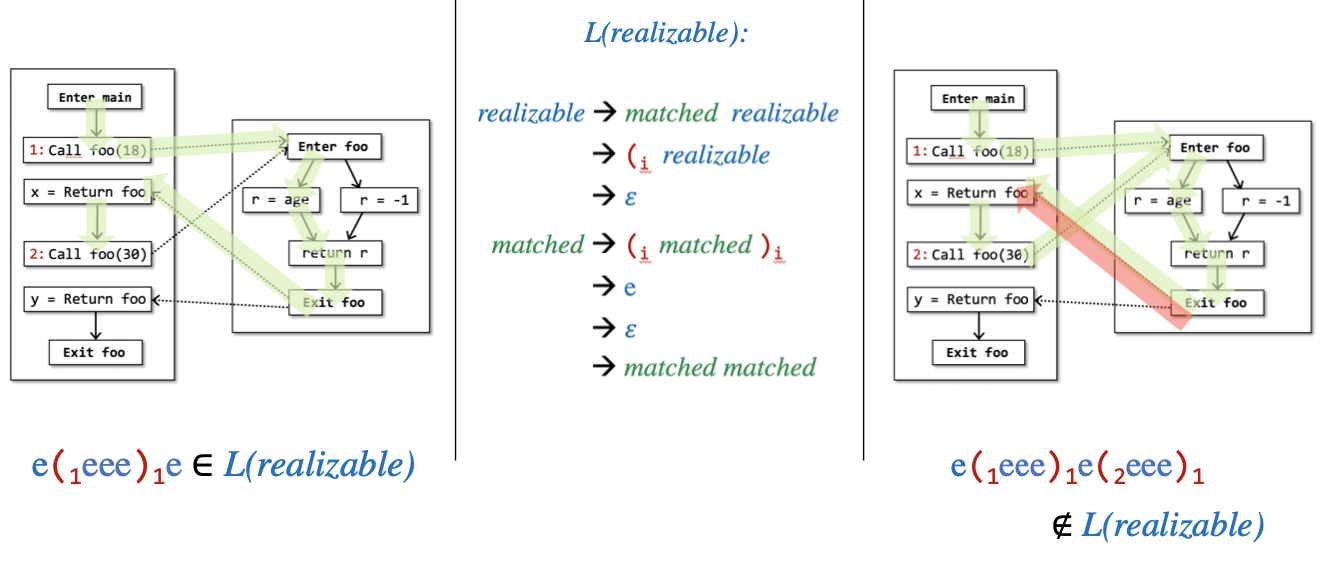
将寻找realizable paths抽象成为典型的括号匹配问题。这里的Partially指的是)i一定会有一个(i匹配,换句话讲就是说对于每一个return-edge都有会有一个call-edge匹配,但是每一个call-edge却不一定有返回值(比如realizable but not infeasiable paths)。问题的整个建模过程为:对control-flow graph上的所有edge都加上一个label,对于一个call语句i,其call-edge被标记为(i其return-edge被标记为)i,而其余所有的edge都被标记为e。
A path is a realizable path if thee path' word is in the language L(realizable).比如
- (1(2 e )2)1(3
- (1(2 e )2)1(3 (4
- (1(2 e e e )2)1(3 (4
- e e(1(2 e e e )2)1(3 (4 e
则根据括号匹配设计的上下文无关文法如下:
realizable ⟶ mathched realizable
⟶ (i realizable
⟶ ℇ
mathched ⟶ (i mathched )i
⟶ e
⟶ ℇ
⟶ mathched matched
IFDS
IFDS是Interprocedural,Finite,Distributive,Subset Problems的简称。总结来就说:IFDS is for interprocedural data flow analysis with distributive flow functions over finite domains.
IFDS将一大类数据流分析问题转化成为了图可达性问题进行处理,相比较于迭代数据流框架提供了多项式时间的精确处理。但是IFDS必须在一定的约束下才可以:
很多普遍的数据流分析问题都是subset problem——集合的union/intersection等;而Interprocedural指的是全程序分析;而该分析问题还有必须有一个distributive flow function并且其domains还是finite才可以用IFDS来处理。
就比如constant propagation就不可以用IFDS处理,因为其domains是理论上所有的常数所以是Infinite,而且该分析本身也不是Distributive。
Overview of IFDS
MRP
跟Intra-procedural analysis使用meet-over-all-paths来衡量分析的精度一样,IFDS也使用meet-over-all-realizable-paths来衡量其分析精度。
根据MOPn = ⊔(p∊Paths(start, n))pfp(⊥)的定义,对于每一个node点n,MOPn表示在CFG上的start点到node点n所有的paths的union/intersection操作。
而根据MRPn = ⊔(p∊RPaths(start, n))pfp(⊥)的定义,对于每一个node点n,MRPn表示在CFG上的start点到node点n所有的realizable paths(这些paths的label构成的word符合realizalble语言的上下文无关文法)的union/intersection操作。
根据两个精度计算方式的定义可以看出,MRPn对那些unrealizable paths进行了剪枝优化,因此其结果也比MOPn更精确——MRPn ≼ MOPn。
Algorithm
首先从总体上概括一下IFDS的算法框架:
输入:程序P,数据流分析问题Q
- 为程序
P建立superGraph G*,并根据分析问题Q为G*的每一个edge定义flow functions(使用𝛌表达式)(可以对比intra-procedural analysis为每一个node建立flow functinos) - 通过将
flow functions转化为representation relations(一种子图)的形式来建立程序P的exploded supergraph G# - 最后在
G#上应用tabulations algorithm就可以将程序Q的分析问题当做图可达性问题从而求解(找到MRP solutions)
Let n be a program point, data fact d ∊ MRPn, iff there is a realizable path in G# from <Smain, 0> to <n, d>.
SuperGraph and Flow Functions
SuperGraph
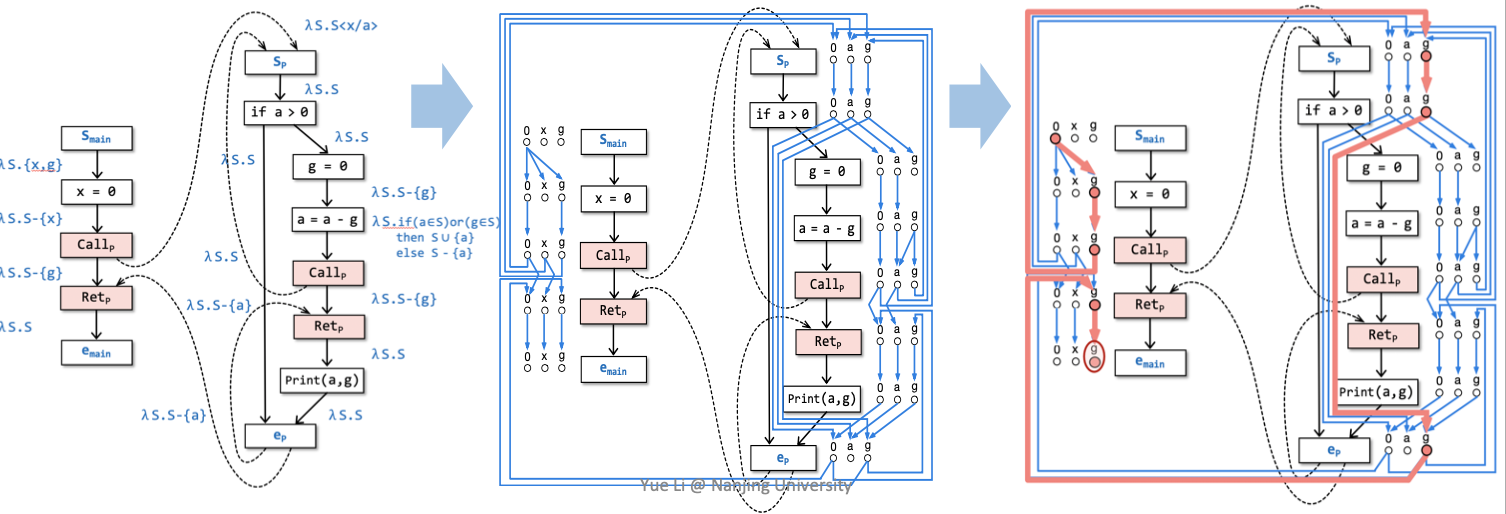
引入supergraph G* = (N*, E*), 对于过程间数据流分析,每一个procedure都是一个控制流图G,每一个G都有一个自己的start nodesp 和exit nodeep。IFDS框架处理的全程序的superGraph G*就是这些控制流图的集合{G1, G2....}。
过程间分析最重要的procedure call则需要一个node点Callp和一个node点 Retp。G*对于每一个procedure call都需要三条边:
intra-procedural call-to-return-site edge:Callp ⟶ Retpinter-procedural call-to-start edge: Callp ⟶ spinter-procedural exit-to-return-site edge: ep ⟶ Retp
Flow Functions
设计flow function是根据具体的程序分析问题,使用𝛌-expression表示的。
Exploded Supergraph and Tabulation Algorithm
Exploded SuperGraph
通过将flow function转换成为representation relations子图来建造exploded superGraph G#。
每一个flow function被一个2(D + 1)个node组成的Graph代表,其中D表示的是一个dataflow facts的有限集合。
这里的representation relationRf ⊆ (D ⋃ 0) X (D ⋃ 0),符合如下规则:
- {0, 0}
Edge: 0 ⟶ 0 - {(0, y)|y∊f(∅)}
Edge:0 ⟶ d1 - {(x, y)| y∉f(∅) and y∊f({x})}
Edge: d1 ⟶ d2
其中0和0之间自动连一条边;如果在没有输入的情况下输出为y则自动连一条0到d1的边;如果输入为x而输出是f并且输入为∅的时候的输出不为y,则需要在两个dataflow facts之间连一条边。
在将superGraph G*转化为exploded superGraph G#的过程中:和传统数据流分析不一样的是——其中的edge代表了一个flow functino。所以在转化时候G*的每一个node都被转化成为D+1个nodes,而一条edge分别连接的两个D+1个nodes(故一个flow function被转化为2(D+1)个node组成的子图)共同被转化成为representation relation子图。
Edge 0⟶0
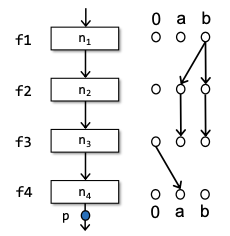
对于一个特定的数据流分析问题,它有D个data facts。但是在构造exploded superGraph的时候为什么一个node需要转换成为D + 1个nodes呢?
回顾一下传统的数据流分析,如果想要确定一个program point是否还保持一个data fact比如definition是否是reachable的,我们需要判断从程序入口到该program point的流动中该data fact是否会传播到该点。
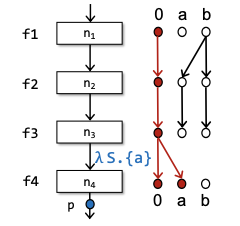
即OUT[p] = f4○f3○f2○f1(IN[n1])。准确的说Data facts are propagated via the composition of flow functions.——这里最重要的是一个composition的概念,实际上对于IFDS框架来说,如何在如图可达性问题中实现这种连接,否则会导致整个分析的结果无法沿着edge进行传播,而Glue Edge:0⟶0便解决了这个问题。
Tabulation Algorithm
最后一步在构建好G#之后,最终在其上应用Tabulation算法来寻找从<Smain, 0>开始的所有realizable paths来决定该分析问题的所有MRP solutions。
理解一下整个算法的核心:
Let n be a program point, data fact d ∊ MRPn, iff there is a realizable path in G# from <Smain, 0> to <n, d>.
首先解释<S,d>指的是在program point点S的一个data fact即d。如果对于一个program point点n,如果在G#上可以从<Smain, 0>到<n,d>有一条realizable path——则就说data fact d在program point n这一点是holds的。
关于该算法的核心暂时不深入理解。比如这里的summary思想也是为了处理同一个方法被冗余处理。
Distributivity
这里我们了解一下IFDS的可分配性Distributivity:
- F(X ^ Y) = F(X) ^ F(Y)
而根据定义,对于处理constant propagation来说比如z = x + y,需要同时考虑两个输入,而IFDS一次只能处理一个输入:F(x)^F(y)。本质上每一个representation relation只能处理如果x存在则...,但是无法处理如果x and y同时存在则...。故常量传播是不可分配的。
In IFDS, each data fact(circle) and its propagation(edges) could be handled independently, and doing so will affect the correctness of the final results.
就是说其data fact和edge都是可以分开处理,到最后一步才进行union/intersection——即可分配性。而Pointer analysis因为需要处理别名alias信息,这样的话需要考虑多个输入信息——故其本质上也不是可分配性的。
Soundiness
虽然所有的程序分析算法都在强调其可以捕捉到所有的程序运行时行为。但是学术界和工业界的理论和工具在实际应用中都会产生unsound的结果。这是因为编程语言本身会有一些Hard Feature导致程序分析无法进行。
- Java: Reflection,native code,dynamic class loading ...
- C/C++: Pointer arithmetic, function pointer...
这些特性使得程序分析精度受损。故学术界引入一个新词Soundiness表示:
A soundy analysis typically means that the analysis is mostly sound, with well-identified unsound treatments to hard/specific language features.