Lab1
Before Lab
Lab1一共有三部分:Bootstrap,BootLoader,Kernel;前两部分都是GDB调试为主,熟悉GDB的调试技巧和操作系统的启动流程。最后实现一小部分monitor中test_backtrace的功能。
如果GDB调试出错,可能是因为调试器没有链接到操作系统上:
1 | add |
PC Bootstrap
Getting Started with x86 assembly
Exercise 1
JOS中使用AT&T格式的汇编语言,在Lab0中介绍了相关资料。实验要求熟悉x86汇编和Inline汇编两种写法。
Simulating the x86
Lab1的工作目录:
/boot目录包含和启动相关的文件。/kern目录包含内核和监视器相关的文件。/lib目录包含一些链接使用的库函数比如printf。/inc目录包含头文件,申明了需要使用的数据结构。/obj目录是make之后相应的反汇编代码,供调试使用。
Lab1主要分析/obj/kern/kern.asm和obj/boot/boot.asm两个文件。这两个文件分别是/boot和/kern目录下的文件编译连接后的目标文件被反汇编而生成的。之所以这样做是因为反汇编之后可以看到每一条指令在内存中的绝对地址。这样调试的时候非常方便。至于实模式和保护模式下的地址转换在后续的实验中也会重点关注。
The PC's Physical Address Space
最早的8086机器只有1Mb的寻址空间,后面的80x86系列机器为了向后兼容所以衍生出实模式和保护模式这两种概念,但是BIOS一直都存在于从0x00000000到0x00100000这1Mb的空间中。JOS的内存布局也是规定只有0x00000000到0x10000000这256MB大小的空间,但是默认地址线是32位的。这个很重要,因为后面实验对JOS进行虚拟内存分配的时候页框地址最大也只能是0x10000000,内核如何处理映射就是一个问题。具体布局见下图:

The ROM BIOS
Exercise 2
这里介绍一下常用的GDB调试参数:
si: 单步调试info register: 查看当前各寄存器的值x/Nx Addr: 查看内存地址Addr之后N字的内容x/Ni Addr: 查看内存地址Addr之后的N条反汇编指令x/Ni $eip: 查看CPU当前执行的下N条指令(其中$eip可以换成不同的寄存器,这里就不一一列举了)
通过分析前面的JOS内存的布局,BIOS作为固件存在于0xf0000到0xfffff这64KB的空间上。注意启动为实模式,CPU的地址线寻址都是20位的。启动仿真器之后看到第一条代码停在了0xffff0的地址上,说明这是BIOS程序的入口。0xffff0到BIOS程序顶部0xfffff只有16字节的空间,需要更大的运行空间,因此第一条指令ljmp $0xf000,$0xe05b;也就是跳转到0xfe05b这个地址正式开始运行BIOS的程序。
BIOS本身也是一个很复杂的系统,但是和OS关系不大。通过调试BIOS的代码我们知道了它的功能:
- 建立中断向量表及相应的中断例程
- 初始化部分硬件及自检(POST)
- 激活
INT 19中断来加载启动盘第一扇区512字节的内容到内存(Linux)
这里应该说明第一扇区的内容是/boot目录下的内容:boot.S和main.c,这两个文件最后被编译链接成为可执行目标文件(这里需要ELF的知识)。在Linux系统中,这个可执行目标文件大小就是512字节,正好放在启动盘的第一个sector中,被称为bootsect。而BIOS的主要工作之一就是将bootsect加载到内存中,执行完任务之后,BIOS跳转到bootsect的初始位置。至此BIOS将权限交给操作系统,OS继续完成剩下的启动过程。 这里发现了一个小问题:就是在查看/obj/boot目录的时候,发现出现了boot.out和boot两个文件,如下:

strip命令将ELF文件中的符号表信息等调试信息删掉,减少文件本身的大小。理论上讲bootsect最后应该被链接到启动盘kernel的第一个扇区上,换句话讲最后的操作系统启动盘只有一个。查看/obj/boot目录下生成的这个两个文件:boot.out的格式为可执行目标文件,boot是x86 boot sector的格式,这两个文件中一定有一个作为bootsect链接使用。见下图:
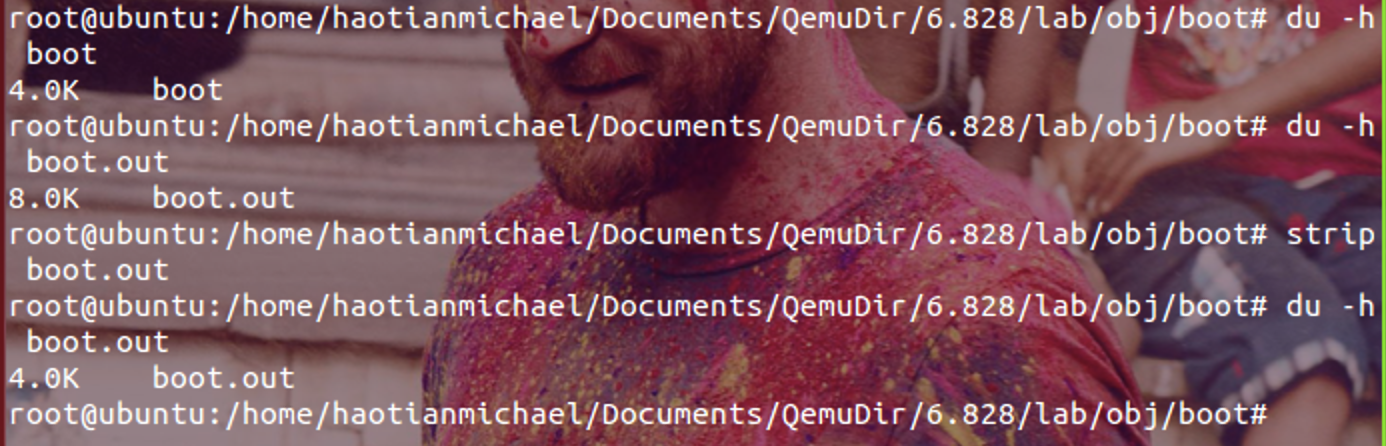
可是经过分析这两个文件大小都是8K,经过优化之后也要4K大小,和512Bytes相差太远。而且文件boot还不可以使用二进制工具分析。这个细节方面应该和链接关系很大,《程序员的自我修养》这本书是国内少有的讲链接装载的好书,有时间再拜读吧。
The Boot Loader
Code
分析boot/boot.S
分析一下/boot/boot.S这个文件:
1 | ##############1.申明部分############### |
申明部分两个宏定义是在保护模式下的段描述符的申明,对于保护模式后面还介绍,这里权把它们看成是CS和DS段寄存器。
实模式部分首先关掉了中断cli,因为接下来就要进行实模式下中断服务例程向保护模式下IDT中断描述符的交接。期间系统无法响应正常的中断服务。cld将标志位DF置零,DF和字符串操作相关;清零段寄存器。并打开了第21(A20)到第32根地址线,在没打开之前高于1MB的地址总是会“回滚”到0,这也是Linux检测保护模式和实模式的一个方法。接下来加载GDT,movl %eax, %cr0这句话是将系统控制寄存器%CR0的第0位(PE位)置一,意味着处理器工作方式变为保护模式。这里没有直接对%CR0进行操作,而是通过%eax来实现主要是为了不破坏寄存器的其他位,值得借鉴。最后ljmp $PROT_MODE_CSEG, $protcseg是跳转指令,需要注意的是现在已经是保护模式了,而在实模式下和保护模式下对于地址的转换方式已经从段寻址变成GDT寻址。这里只需要知道跳转到了protcseg这个地址。
保护模式初始化了重要的段寄存器,然后跳转到boot/main.c/bootmain函数,开始将启动盘剩余的内核部分载入内存。注意在AT&T格式的汇编语言中,操作数的字长是由操作符的最后一个字母决定的,后缀'b','w','l'分别表示字节(byte:8位),字(word:16位)和长字(long:32位)。
数据区部分都是在保护模式下建立GDT全局描述符的时候相关的宏定义。
分析boot/main.c
分析一下boot/main.c这个文件:
1 | #define SECTSIZE 512 |
先看这两个宏定义,SECTSIZE是磁盘一个sector的大小,一般读写操作都要求地址对齐,这个宏定义就会派上用场。ELFHDR是一个指向ELF文件结构体的指针,不得不说强转是C语言最有力的工具之一,由此可知0x100000便是内存载入的首地址。这个地址也是BIOS程序结束的地方,可见JOS对于内存的规划分配还是很精确的。
1 | void |
readseg函数中的对齐,看下面这个sample函数:
1 | #include<stdio.h> |
之所以需要对齐,因为磁盘和内存之间读写如果按照规定的最小粒度进行,CPU的访问性能会提高。具体见IBM.alignment。上述函数的执行结果见下图:

readsect函数都是一些端口操作。也没仔细研究Orz。下面主要看一下bootmain函数剩下的部分:
1 | ph = (struct Proghdr *) ((uint8_t *) ELFHDR + ELFHDR->e_phoff); |
关于JOS对于ELF文件的申明见/inc/elf.h。一共有三个结构体,Elf代表文件头;Proghdr代表加载时候segment的信息;Secthdr代表运行时section的信息;
在Lab0中,我们分析过对一个程序加载的时候是以segments为最小粒度的。所以我们重点关注Elf和Proghdr这两个结构体的细节。
e_phoff: segment表在整个程序中的偏移量e_phnum: segment表项的个数ph->p_pa: 该segment在内存中的加载地址ph->p_memsz: 该segment的大小ph->p_offset: 该segment相对于表起始地址的偏移量
所以ph就是segment段表的开始地址。而eph就是segment段表的项数。这个循环是把所有的segments都加载到相对应的内存地址中。
加载结束后,再次跳转((void (*)(void)) (ELFHDR->e_entry))(),通过调试反汇编代码,发现跳转的这个地址为call *0x10018,注意这里是一个指针,可以看到内核函数真正的入口在0x0010000c。所以正确的操作见下图:

Exercise 3
在上面分析的过程基本上回答了所有的问题:
%CR0标志位的改变意味着实模式切换到保护模式call *0x10018是最后一条BootLoader执行的指令,movw $0x1234, 0x472是内核第一条指令,这条指令在0x0010000c这个入口地址。- 通过读取ELF文件中关于加载segments的信息,因为main函数最开始加载了8个sectors的内容到内存中,这部分内容就是和ELF格式和细节信息有关系。
Loading the Kernel
Exercise 4
重温C语言指针,实验中推荐TCPL。分析实验中给出的部分示例代码,体会指针的魅力:
1 | c = (int *) ((char *) c + 1); |
这段代码将c强转成为char类型的指针之后加一,然后赋值为500;问题就出现在char类型和int类型的指针大小是不一样的。int类型为4个字节,而char类型只有1个字节;所以这样势必会导致赋值的时候改变数组中原来的布局。已知a[1]原来的值400,16进制为0x190;a[2]的值原来为301,16进制为0x12D;500的16进制为0x1F4;一个地址单元为一个字节,为见下图:
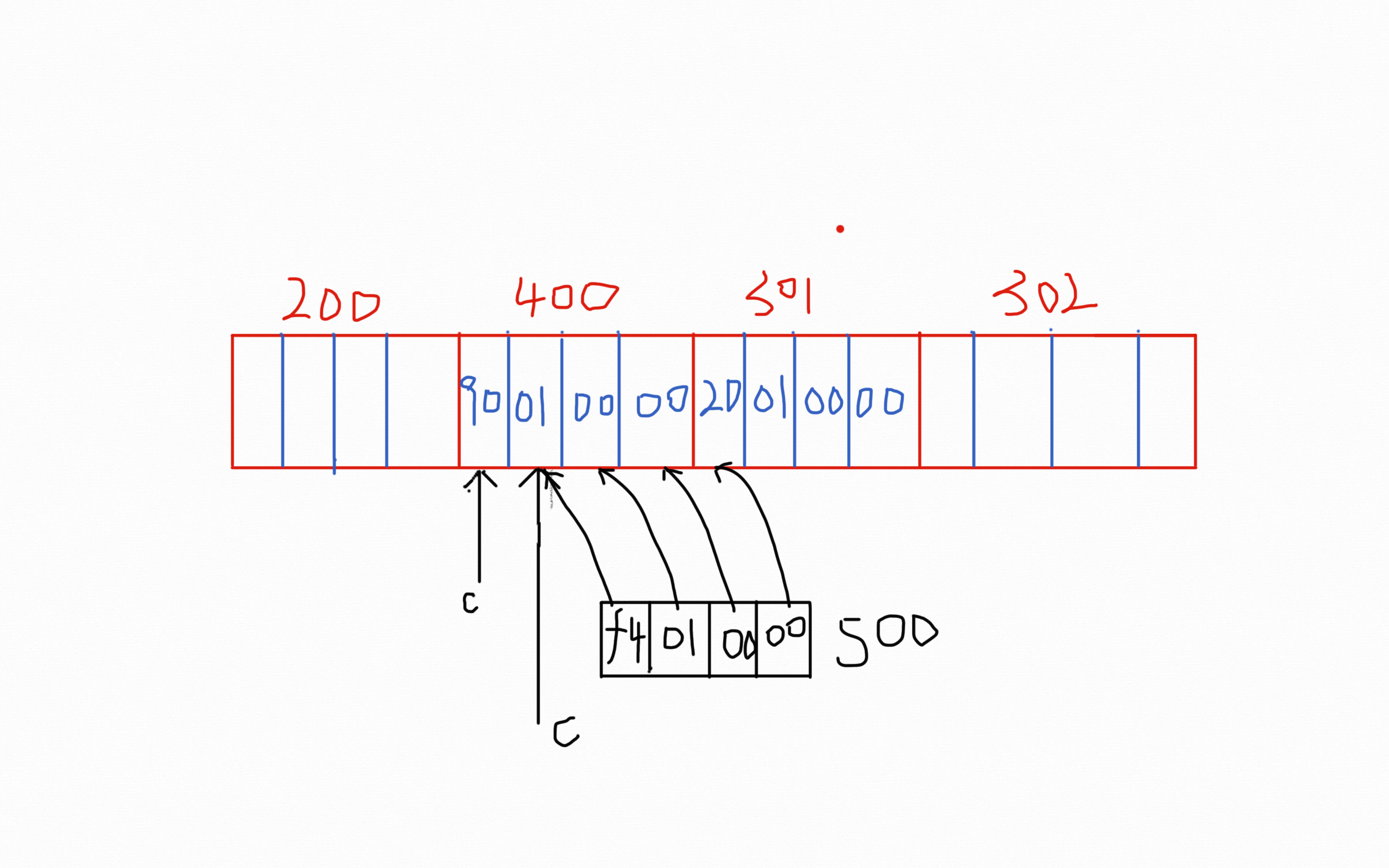
可以看到读写操作是按照字节为最小单元,最后导致a[1]的值变成0x1F490也就是十进制的128144;而a[2]由于被抹掉以个字节,所以变成0x100也就是256。下图是最终的运行结果:
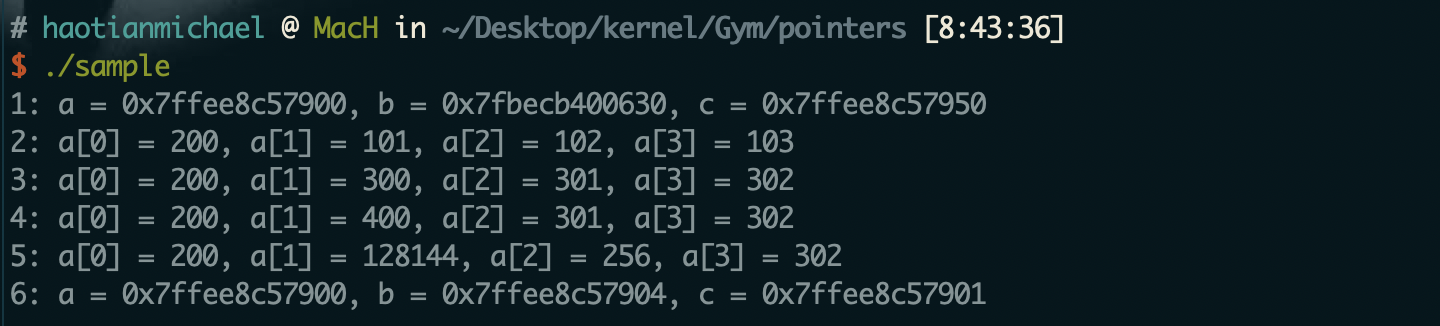
Exercise 5
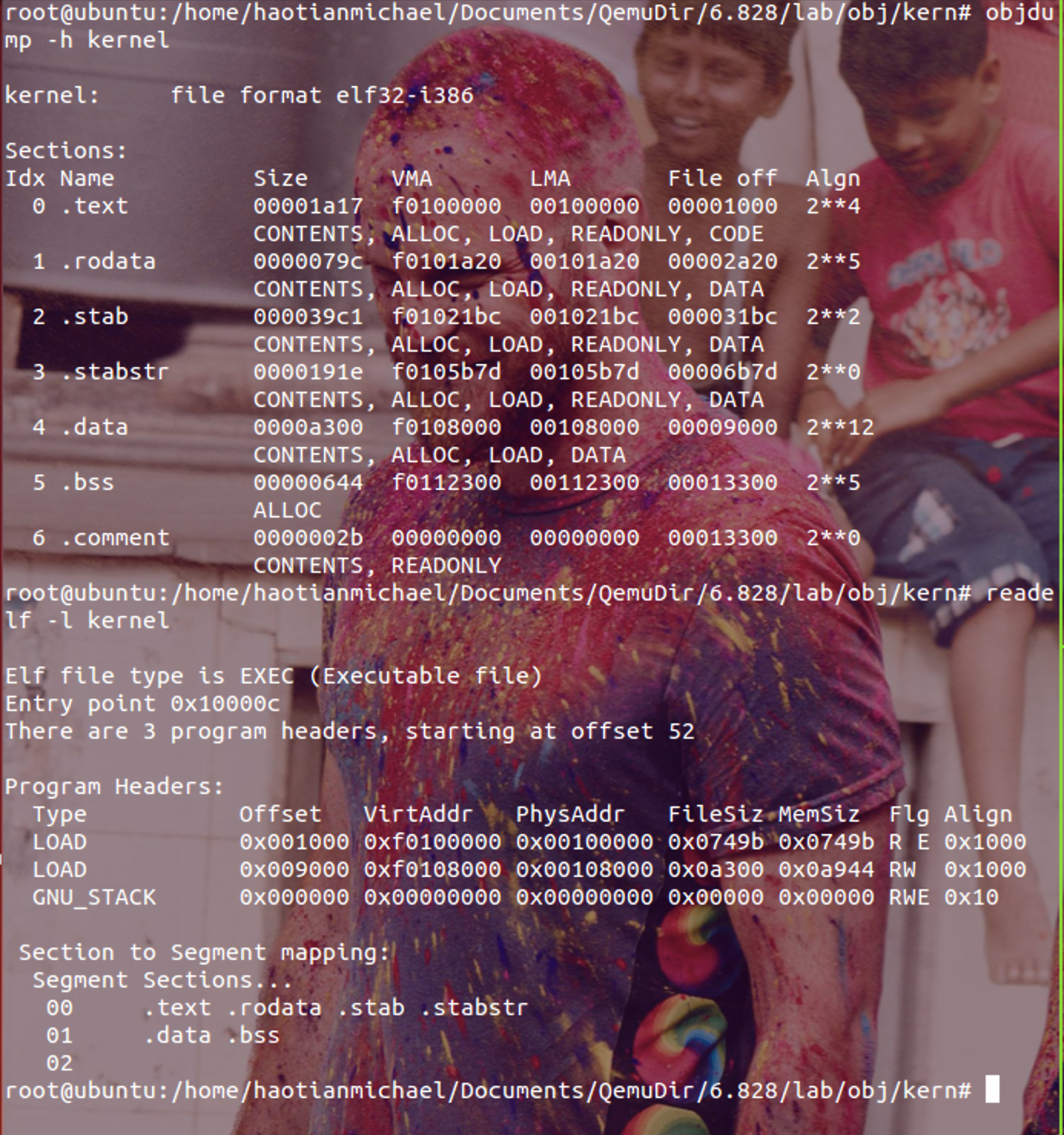
关于链接器和加载器,最经典的当然是这本loader and linker。这是中译本ll.Ch。不过我做实验的时候没有想明白他们为什么要在这里引入这两个复杂的概念;题目很简单,但是不知道LMA和VMA是和虚拟内存有关系还是和链接器,加载器有关系。后来用readelf -h kernel发现VMA就是虚拟地址,所以这里他们所谓的linking address和loading address只是实验中自行定义的字面意思加载的地址和执行的地址,和链接器加载器没有关系!!另外在Lab0中已经分析过加载时候的section是所有sections组合成的一个聚合节,这里不考虑链接时候的单个section的概念。这样的话,就可以明白实验讲解的思路————引入使用ELF中segments的概念来解释加载过程,而加载过程时候已经开启了分页机制,所以这时候用loading address和linking address来解释0xf0100000和0x00100000的区别。而实际上0xf0100000就是映射到0x00100000上,相关细节在Kernel部分会继续分析。 readelf和objdump的操作见下图:
将链接地址改掉之后,第一条报错的应该是和链接地址直接相关的指令,跳转指令ljmp $PROT_MODE_CSEG, $protcseg;
Exercise 6
前面分析过#define ELFHDR ((struct Elf *) 0x100000)所以我们可以知道,内核的装载地址(load address)就是0x00100000,而内核开始执行的地址应该是e_entry也就是0x0010000c。从BIOS到BootLoader的时候,内核还没有开始装载。所以0x00100000是空的。

The Kernel
Using virtual memory to work around position dependence
Lab1中的地址映射: 0x00000000————0x00400000映射到0x00000000————0x00400000;0xf0000000————0xf0400000映射到0x00000000————0x00400000;
在实验过程中关注了一下地址: 在执行到kern/entry.S文件之前,所有的内存地址都是物理地址(书中代言为线性地址,但是线性地址=物理地址所以没有太大区分)。直到%CR0寄存器的PG标志位被置零。这时候分页机制才被激活。0x00100000和0xf0100000都映射到0x00100000,所有两个地址存储的数值是一样的。而在映射还没有建好之前是不一样的。
Exercise 7
%CR0寄存器PG位控制分页机制的实现。看到mov %eax, %cr0执行结束之后,索引地址变成了0xf0100010。地址映射不对,第一条错误的指令一定会是跳转指令jmp *%eax。具体的分页细节在Lab2中分析。实验操作见下图:
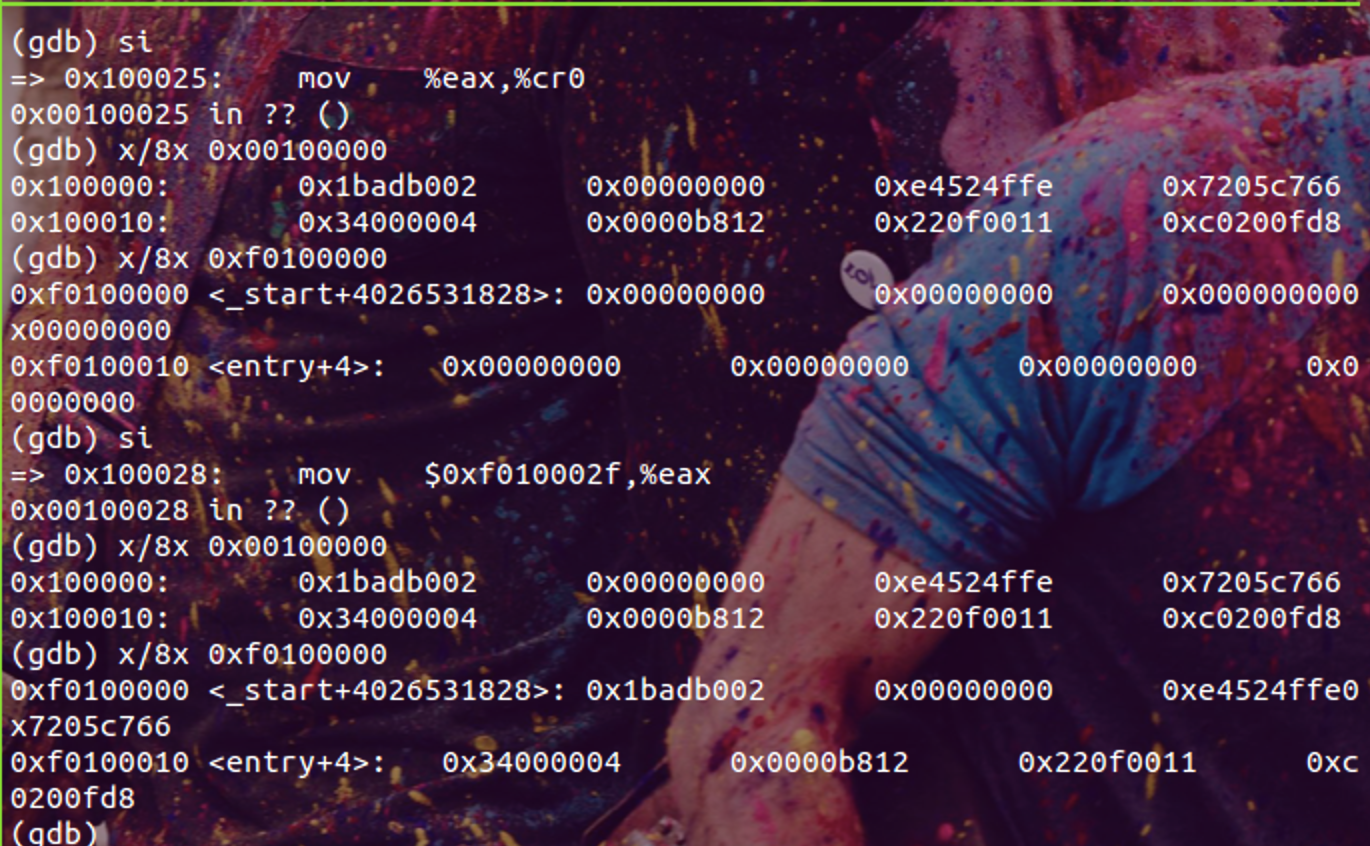
Code
分析kern/printf.c
下面分析一下kern/printf.c这个文件:
1 | static void putch(int ch, int *cnt) |
cprintf是主函数,这里用到了C语言的变参特性。变参在C库stdarg.h中定义至少要有一个固定的参数:fun(const char *fmt, ...)。主要有三个宏组成:
va_list: 申明可变参数指针ap,依次指向省略号表示的可变参数va_start(ap, lastFix): 初始化ap,开始指向第一个可变参数va_arg(ap, type): 将ap指向下一个可变参数va_end(ap): 清除ap指针,结束函数
可以看到变参fmt和变参指针ap被一路传到vcprintf———>vprintfmt。在vprintfmt中使用。该文件中重点关注两个函数:
- 在
lib/printfmt.c中的函数:vprintfmt(void (*putch)(int, void*), void *putdat, const char *fmt, va_list ap) - 在
kern/console.c中的函数:cputchar(int c)
经过观察之后就可以知道: vprintfmt函数判断字符串输出参数的类型并调用cputchar函数将相应的输出显示到显示屏上。
在函数分析之前再介绍一个vim的新技能:搜索高亮:match Search /xxx/,可以对现在正在关注的关键字进行高亮显示,调试的时候很有用:

分析函数vprintfmt
vprintfmt函数其实很简单,主体就是一个while循环:在遇到%之前直接输出,遇到%之后开始判断格式并输出。
分析函数cputchar
在vprintfmt函数中需要注意一个变量:ch = *(unsigned char *) fmt++。ch代表了当前ap指针指向的变参,也就是我们需要输出的内容。cputchar(ch)中的参数正好就是这个ch。我们使用Ctags跟踪这个ch参数经过的函数:putch(int ch, int *)————>cputchar(int ch)————>cons_putc(int ch)。现在基本上可以看清所有的控制台输出操作都是定义在console.c文件中的。我们直接分析一下cons_putc(int ch)这个函数:
1 | static void cons_putc(int c) |
上三个子函数都涉及到的内联汇编inb()和outb()两个函数在inc/x86.h中有定义。其中serial_putc是串口输出,lpt_putc是并口输出,而cga_putc是显示屏输出,具体不细分析了:
1 | for (i = 0; !(inb(0x378+1) & 0x80) && i < 12800; i++) |
另外,在cga_putc(c)函数中,有一段代码:
1 | if (crt_pos >= CRT_SIZE) { |
我们知道cga_putc(c)函数是用于显示屏输出的函数,而查看这几个宏定义:
1 | static uint16_t crt_pos //光标 |
简单来讲就是如果输出满屏之后,需要页面向上滚动一行。
Formatted Printing to the Console
Exercise 8
经过上面的分析之后,知道格式化输出是在kern/printfmt.c/vprintfmt()这个函数中。找到相应的位置修改就行。
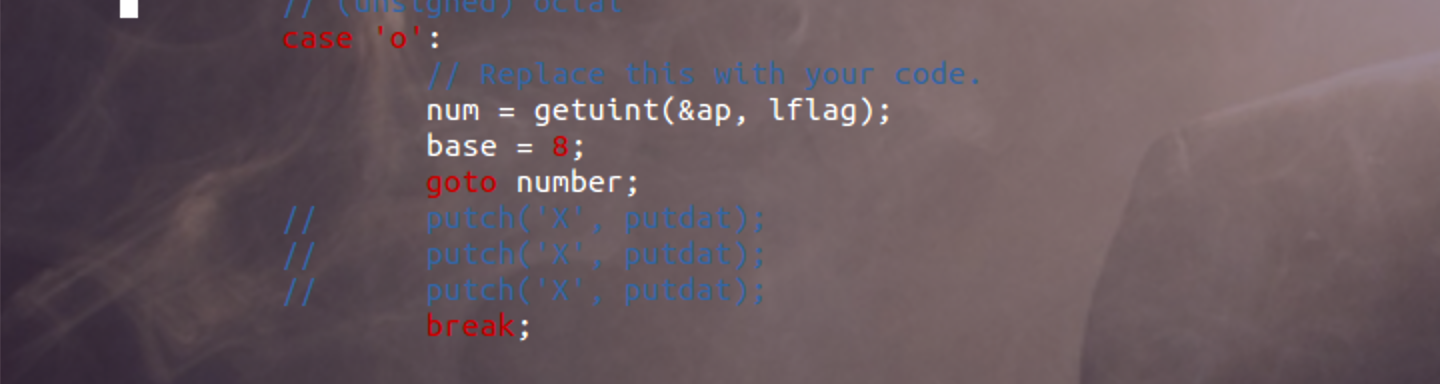
Questions
这是Exercise.8后面的一些问题,当然很简单了:
1.cputchar(int c) 2.一句话,就是满屏时候的处理方法 3.主要是变参指针ap和格式化变参fmt的指向问题,之前分析过
4.将代码加到kern/monitor.c中,输出见下图。因为57616的十六进制就是ell。而0x0x00646c72在小端存储的机器上用char*表示就是rld\0。如果想要用大端存储的话,只要反过来就行0x726c6400。

5.根据变参的定义,如果fmt参数不够,那最终ap指针会指向一个未知内存区域。所以输出的数不一定。见下图:

6.关于变参的定义是在inc/stdarg.h中,我们看一下va_arg是如何一次一次取出变参的:
1 | #define va_arg(ap, type) __builtin_va_arg(ap, type) //Fall 2018 |
可以看到va_arg是通过地址往后增长来取出下一个变参的。而正常编译器是从右往左的顺序将参数入栈的(因为栈是从高地址向低地址延伸的)。如果这时候栈的顺序变了,那只需要将va_arg函数中的对地址的加法改为减法就行。
The Stack
Exercise 9
关于栈的定义在kern/entry.S中。见下图:
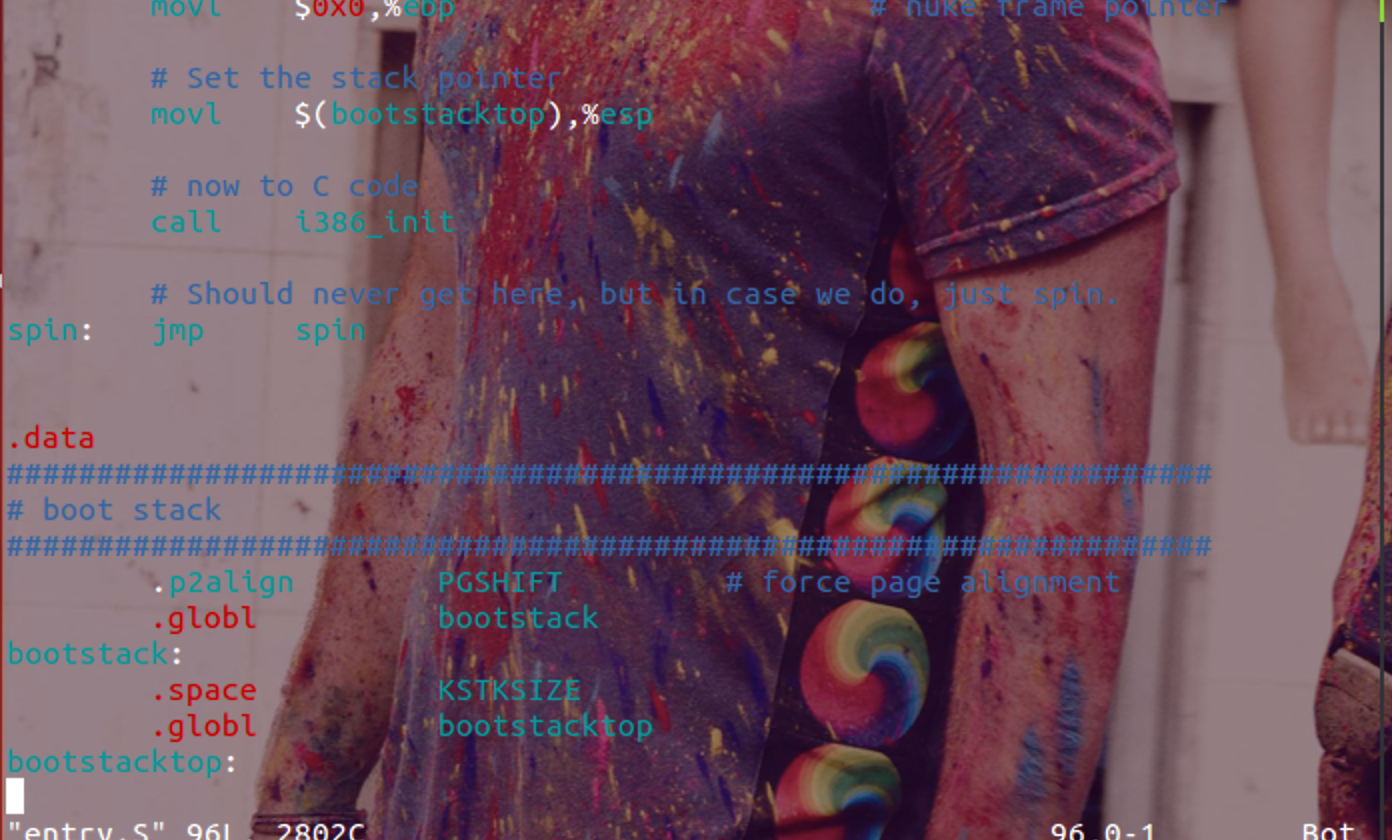
因为栈是从高地址向低地址延伸的,所以mov $(bootstacktop) %esp将栈顶地址赋值给%esp寄存器。而在数据段中对栈大小的定义也很清楚了————KSTKSIZE是一个宏定义,大小为8x4KB=32KB。
Exercise 10
需要深入了解栈调用的机制,就需要了解stack pointer%esp和base pointer%ebp这两个寄存器的用法。我们通过调试test_backtrace()函数来深入了解。(实际上只要有函数调用就会有栈,但很明显test_backtrace不是第一个调用的函数。当然你也可以从第一个函数i386_init开始,这个时候%esp也刚刚完成初始化0xf0110000,感觉会更爽一些)。
test_backtrace函数的调用发生在kern/init.c/i386_init()中,所以我们第一个断点设置在0xf01000de。从反汇编代码中可以看出,开始调用test_backtrace之前,还有两条指令:
1 | movl $0x5, (%esp) |
在还没有开始执行的时候,查看一下寄存器的状态info registers:%esp的值为0xf010ffe0,%ebp的值为0xf010fff8。
然后开始执行第一句,将参数5movl到栈顶,注意这里不是压栈而是直接存进去的,所以栈指针%esp是不会移动的。但是这时候栈顶元素应该是0x5。我们可以通过info registers命令和x/8x $esp来分别验证,效果如下:

在看一下第二条指令call f0100040。call指令可以分成两条指令:push %eip和jmp 0xf0100040。所以看到push指令是正宗的压栈指令,这时候%esp寄存器的值是要-4的,而且递减满堆栈的顺序是先-4,再压栈。这次栈顶元素应该是下一条指令的地址0xf01000ea,而且%esp的值还得-4。我们可以通过info registers和x/8x $esp来分别验证:

第三条指令就正式进入到test_backtrace函数内部了。分析一下函数内部的调用代码:
1 | void test_backtrace(int x) |
基本上所有被调用的函数开头都会有这两条指令:push %ebp;mov %esp, %ebp;
实验指导书上也解释了%ebp寄存器的作用:On entry to a C function, the function's prologue code normally saves the previous function's base pointer by pushing it onto the stack, and then copies the current esp value into ebp for the duration of the function.每一个函数都有一个%ebp值,作为函数的栈帧,需要在每次调用新函数的时候压栈以保存上一个函数的返回地址。
这个时候莫名其妙的压栈了一个寄存器%ebx。我们将%ebx全局高亮显示发现,后面紧接着会有mov 0x8(%ebp), %ebx。那0x8(%ebp)存储的到底是啥?不难想到就是参数5。然后%esp指针接着扩展当前函数的栈空间。关注一下第二次调用test_backtrace(),前一条指令mov %eax, (%esp)和第一次调用的时候完全一样,而%eax中存的也是参数5-1=4;当然调用指令call也需要一次压栈。总结一下,如果是从push %ebp开始算起是函数栈的开头的话,那我们每一个函数调用会花费4(push %ebp)+4(push %ebx)+20(sub $0x14,%esp)+4(call)一共是32Bytes字节的空间。所以整个栈的布局见下图:
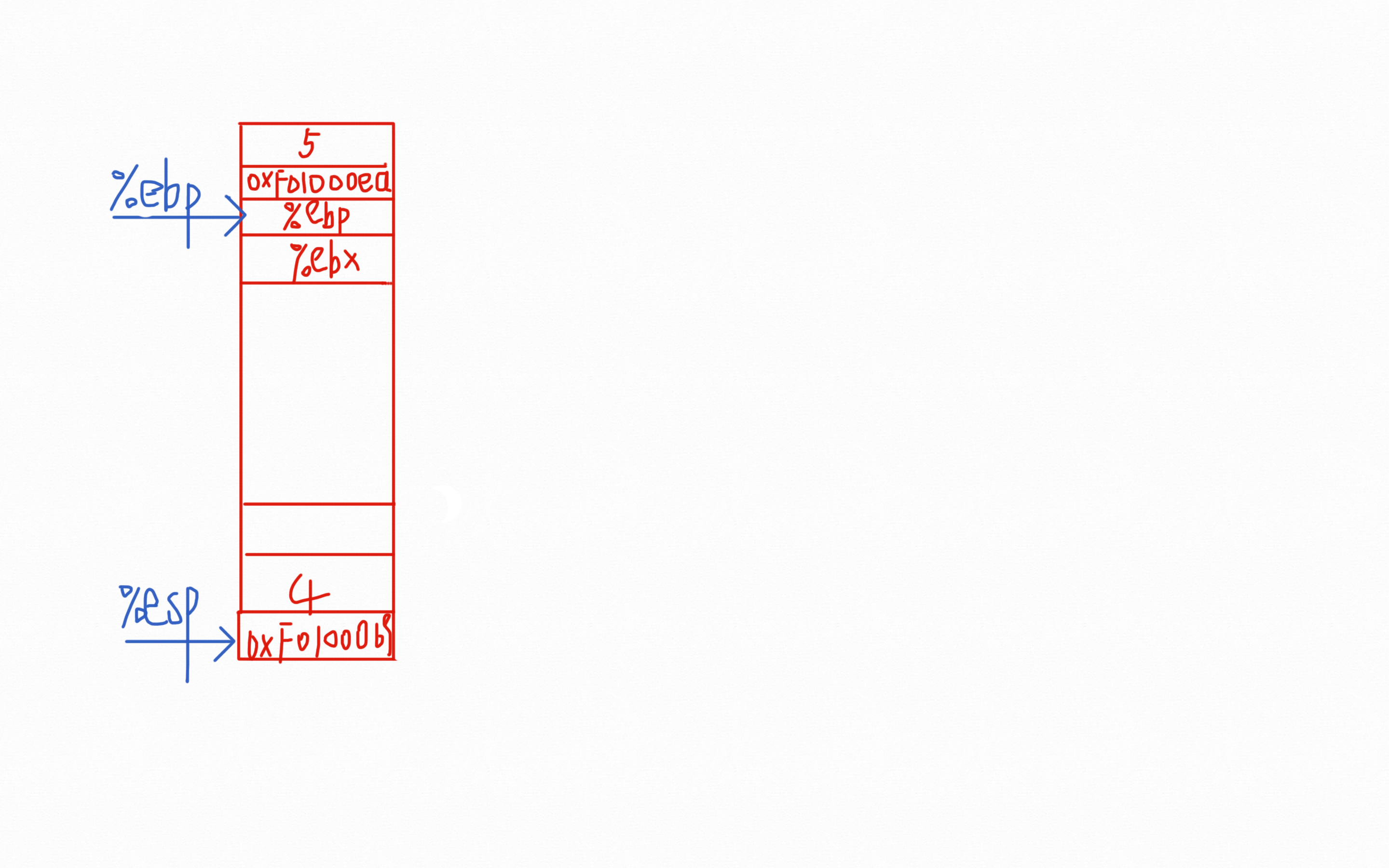
当然在调用过程中还调用了cprintf()这个函数,不过20字节用来分配栈空间也够了。
Exercise 11
经过上面的分析,栈的布局已经很清楚了。所以我们需要知道对于read_ebp()函数来说读出的是当前%ebp指针指向的地址,所以按照上面栈的布局:(%ebp)-->上一个%ebp,0x4(%ebp)-->%eip,0x8(%ebp)-->参数1...当然这里的参数比5个少。
下面就是考验C语言的时刻,一定要注意格式:
1 | int |
Exercise 12
对每一个%eip,尝试着给出其文件名称,函数名称和行号。这些信息都属于调的信息。实验要做的是找到这些调试信息,并按照规定格式将它们输出。这里需要了解STAB符号表的概念。
首先查看下kern/kernel.ld链接脚本。发现了有关_STAB_*的两个信息————.stab和.stabstr。其中stab是今天的重点。kern/kdebug.c中的宏定义说明了stab和stabstr的关系。
1 | extern const struct Stab __STAB_BEGIN__[]; // Beginning of stabs table |
再看一下inc/stab.h对stab定义的数据结构:
1 | // Entries in the STABS table are formatted as follows. |
通过objdump -G obj/kern/kernel来查看当前ELF文件中的符号表信息。见下图:

仔细观察上图,发现每一列的分类就是按照stab数据结构分类的。重点关注一下n_type这个关键字,它表示该描述项的符号类型,上图中出现有很多SO,FUN...等符号类型。将这些列单独列出来进行对比:
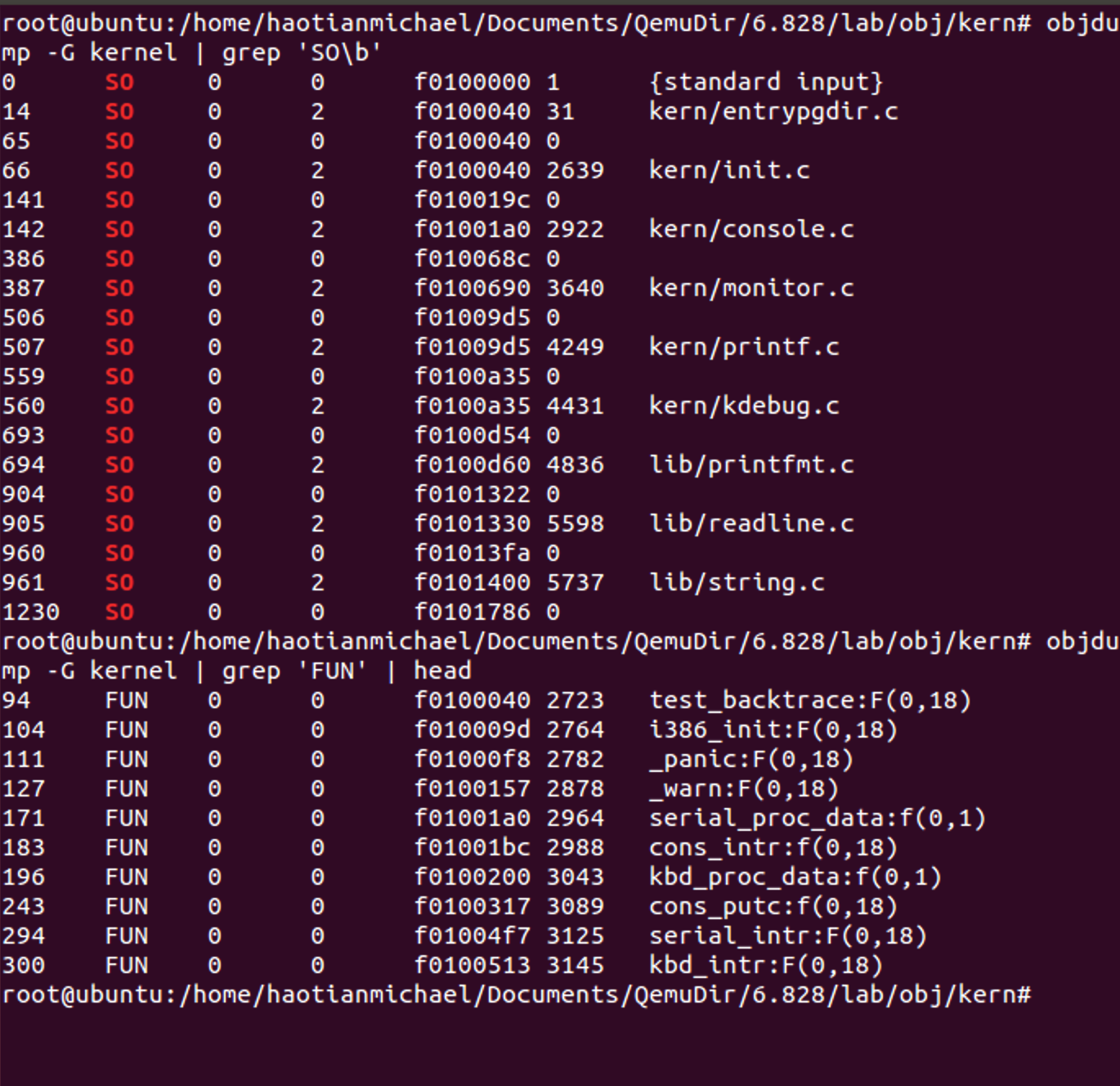
很明显SO指的是文件名,FUN指的是函数名。注意这是objdump对应的符号表,JOS对符号表有自己定义的数据结构见inc/stab.h。输出的顺序都是按照地址来排序的,很整齐。所以stab_binsearch()查找函数原理也就猜的差不多了,这些调试信息和相应地址的关系是通过符号表来连接的。当然所有的这些知识都可以通过kern/kdebug.c这个文件中对stab的注释(见过最全的注释了)学习到。所以我们最后分析一下这个文件:
整个文件一共有两个函数debuginfo_eip和stab_binsearch。JOS建立了一个数据结构Eipdebuginfo用来存放调试信息,debuginfo_eip调用stab_binsearch函数完成一个实例化的Eipdebuginfo,所有的输出信息其实最后都存储在这个实例中。
1 | struct Eipdebuginfo { |
stab_binsearch(const struct Stab *stabs, int *region_left, int *region_right, int type, uintptr_t addr)函数本质上就是一个二分查找。type指的就是符号表项的符号类型,该函数每次查找的时候都需要确定查找的符号类型。我们需要完成的部分是行号,通过检查inc/stab.h文件,很容易知道行号的宏定义是S_LINE。二分查找失败的标志就是LeftA > rightA。所以代码也很简单了:
1 | // Your code here. |
最后将monitor的命令补充完整就更简单了:
1 | add : |
运行结果见下图:

实验过程中有几处细节涉及到编译器的优化,因为还不是很了解编译链接的细节和原理,所以被我忽略掉了。
至此Lab1结束。